You're reading for free via D's Friend Link. Become a member to access the best of Medium.
Member-only story
A quick start to RAG with a local setup

To read this story for free check out this link.
Imagine heading over to https://chatgpt.com/ and asking ChatGPT a bunch of questions. A pretty good way to pass a hot and humid sunday afternoon if you ask me. What if you had a bunch of documents you wanted to decipher? Perhaps they are your lecture notes from CS2040. Now ask the LLM a question: “What did the professor highlight about linked lists in Lecture 4?”

The model spits out a bunch of random information. Let’s say someone magically types in some information (read: context) to the model to help with this.
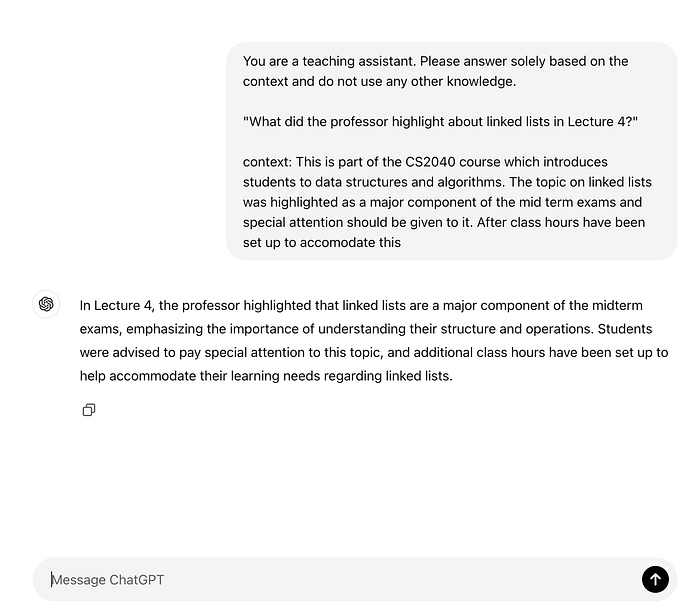
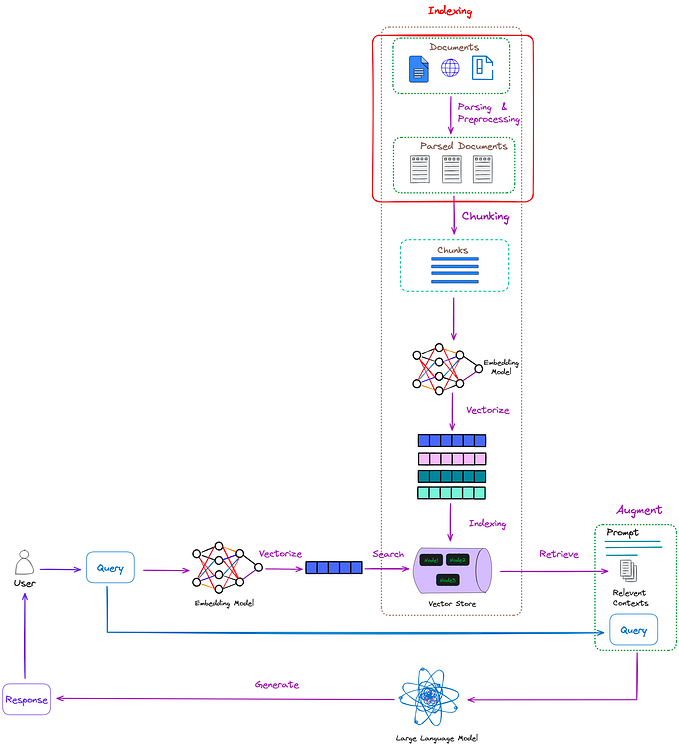
You have to admit it’s naive to always provide the model with context. Is someone always going to have to type this out? Well you are in luck! Retrieval-Augmented Generation does just that! The idea is that a query is vectorised and used to search against a pre-vectorised set of information in a database to retrieve the top few matches based on a similarity algorithm. These matches are returned to the LLM as context for it to answer questions. What are we waiting for? Let’s get started!
Start Ollama
First let’s get the Ollama Server up and running. Ollama is a tool that allows us to load models locally for testing.
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaYou will know this is successful when you head over to localhost:11434and see the words “Ollama is running”.
Start a python environment
Any python environment is fine but I personally enjoy using the langchain image.
docker pull langchain/langchain
docker run -it --network host langchain/langchain shInstall dependencies
apt update
apt upgrade -y
apt install vim tmux -yCreate a working directory
mkdir test && cd test
sudo apt install python3.9-venv
python3.9 -m venv .venv
source .venv/bin/activateInstall python packages
pip install ollama PyPDF2 numpy faiss-cpu copyTransfer the pdf from your computer to the docker container
Download a pdf. It can be any pdf from anywhere.
# This command should be run on your local computer NOT in the docker container
# Take note that the id should be that of langchain/langchain which can be found using docker container ls
docker cp 2210.03629v3.pdf <container_id>:testAdd the boiler plate code
import ollama
import PyPDF2
import numpy as np
import faiss
import copy
ollama.pull("llama3.2:1b")
ollama.pull("all-minilm")
# Load the PDF
def load_pdf(file_path):
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text() + "\n"
return text
def get_embeddings(text):
# Use the embed method from Ollama
embeddings = ollama.embeddings(
model="all-minilm",
prompt=f"{text}"
)
return np.array(embeddings["embedding"]) # Ensure this returns a NumPy array
# Initialize FAISS index
def create_faiss_index(embeddings):
index = faiss.IndexFlatL2(embeddings.shape[1]) # Dimensionality of embeddings
index.add(embeddings)
return index
if __name__ == "__main__":
pdf_text = load_pdf('2210.03629v3.pdf')
# Split the text into manageable chunks if necessary
text_chunks = pdf_text.split('\n') # Splitting by paragraphs or other logic
print(f"chunks: {text_chunks}")
text_chunks = text_chunks[:-1]
text_chunks_copy = copy.deepcopy(text_chunks) # Create a deep copy of text_chunks
print(f"chunks: {text_chunks_copy}")
# Get embeddings for all text chunks
embeddings = np.vstack([get_embeddings(chunk) for chunk in text_chunks]) # Stack into a 2D array
# Create FAISS index
faiss_index = create_faiss_index(embeddings)
# Perform a query (for demonstration)
query = "Your query here"
query_embedding = get_embeddings(query)
D, I = faiss_index.search(query_embedding.reshape(1, -1), k=5) # Top 5 results
print(f"The value of I is: {I}")
# Retrieve the actual text corresponding to the indices
context_texts = []
for idx in I[0]:
print(f"the chunk is: {text_chunks_copy[idx]} and the index is: {idx}")
context_texts.append(text_chunks_copy[idx])
context = " ".join(context_texts) # Join the texts into a single string
print(f"The context is: {context_texts}")
question = "What is the gist of this paper?"
response = ollama.chat(model='llama3.2:1b', messages=[
{
'role': 'user',
'content': f'answer this question: {question} based on the context: {context}. Do not deviate.',
},
])
print(response['message']['content'])
ollama.delete("llama3.2:1b")
ollama.delete("all-minilm")Code Explained
There are a few broad steps.
- Read the pdf
pdf_text = load_pdf('2210.03629v3.pdf') - Chunk the text
text_chunks = pdf_text.split('\n') - Embed the chunks
embeddings = np.vstack([get_embeddings(chunk) for chunk in text_chunks]) - Search for the query
- Pass the context to the LLM
This is part of a larger series. Check out previous articles if this is your cup of tea.
Get started with Agentic workflows
Use this link to read this article for free
parkerrobert.medium.com